During my journey to educate myself on computer science topics that were not covered in my undergraduate University curriculum, I have come across a number of new concepts that have eluded the general discourse in computer programming, one of which is the “trie” structure, pronounced “tree” or “try” (to differentiate it orally). According to the person who defined it:
As defined by me, nearly 50 years ago, it is properly pronounced “tree” as in the word “retrieval”. At least that was my intent when I gave it the name “Trie”. The idea behind the name was to combine reference to both the structure (a tree structure) and a major purpose (data storage and retrieval).
Edward Fredkin, 31 July 2008
Nice trie, but I’m not buying it.
Because of this lackadaisical naming, nobody has a clue what a “trie” is, or how to pronounce it, just by looking at its name. This failure to name concepts properly is a pervasive problem in the computer science industry and has a major toll on our ability to study and learn the subject in conjunction with all the other topics and domain specific knowledge we must learn. A data structure that is this critical to computer science should have a more intuitive name!
So, the next time you are in a position to name something well, don’t just “trie”. Do. Or do not. There is no “trie”!
Better Names
According to Wikipedia, other names for this structure are digital tree, radix tree or prefix tree. The concept of a radix, outside the context of number theory, is opaque and ill-defined and should not be used. “Digital tree” is also nondescript and should have been immediately removed from computer science vocabulary. Every tree represented on a computer is a “digital tree”. This one is no more or less “tree-y” than the others. Of the three, Prefix tree is the most sensible name.
The prefix tree is a natural choice for dictionaries, since it allows you to validate whether a series of characters is a valid string. In general, it allows one to store and validate unique paths discovered in any kind of sequential data. This data structure is a natural choice for modeling unique decision paths taken in turn-based games, such as chess. It would make sense to call this a “dictionary tree” or “sequence tree”.
What is a prefix tree/trie?
A prefix tree is a type of tree data structure that is designed to store strings of characters by organizing the characters based on their common predecessor.
[a,n,t]
[a,u,n,t]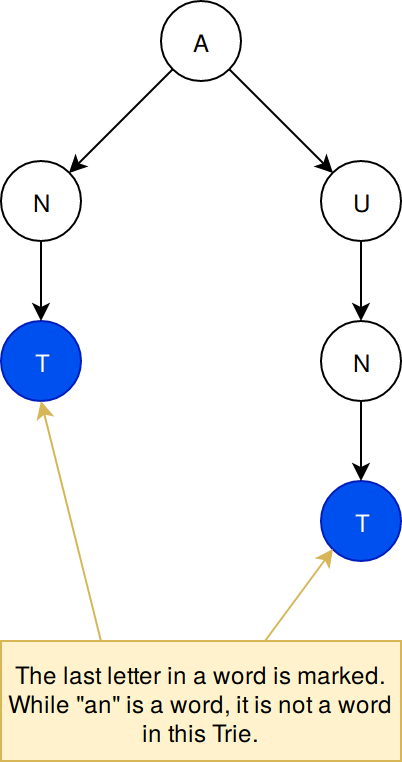
For example, the words “ant” and “aunt” share the same first letter, ‘a’, which is their common predecessor. As each letter in the string [a, n, t] is read, it is added as a new node. Each subsequent letter is connected to the previous letter, forming a path along the branches. When adding the second string, [a, u, n, t], the process starts over from the root node and each node is checked to see if the letter’s node already exists. Since the ‘a’ node already exists as the top level node, it is traversed, and the next character is read from the input string. If the letter is not identified, it is added as a new node, creating a new branch.
When a word is finished, the last node is marked as an endpoint (leaf). The endpoint retains its mark, even if storing a new word adds child nodes to it.
In general, this kind of organization is termed a “parent” and “child” relationship, in which the node that comes after a node is its “child”, and the original node is the “parent”.
When more strings are added, if the new string starts with a different character, it becomes necessary to keep track of all top level nodes using a root node.
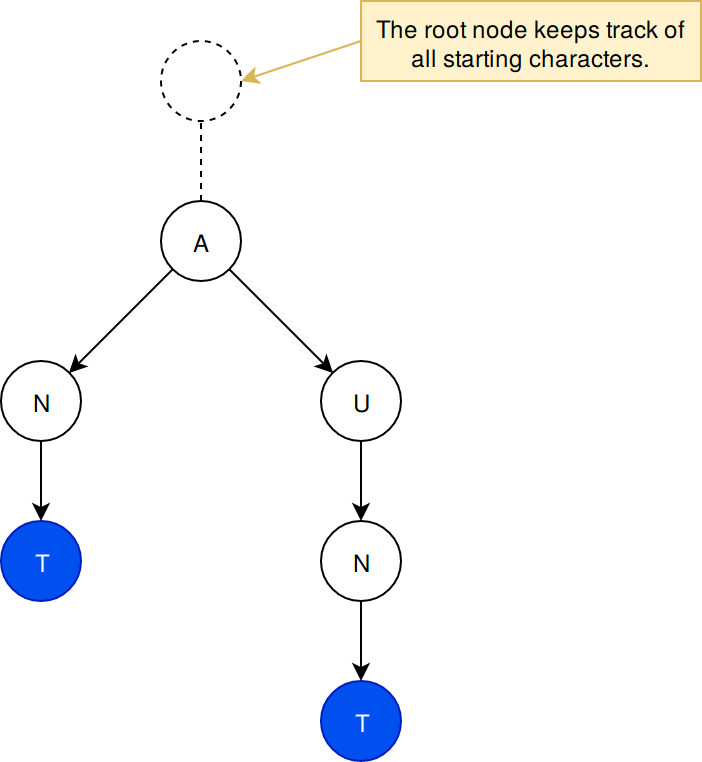
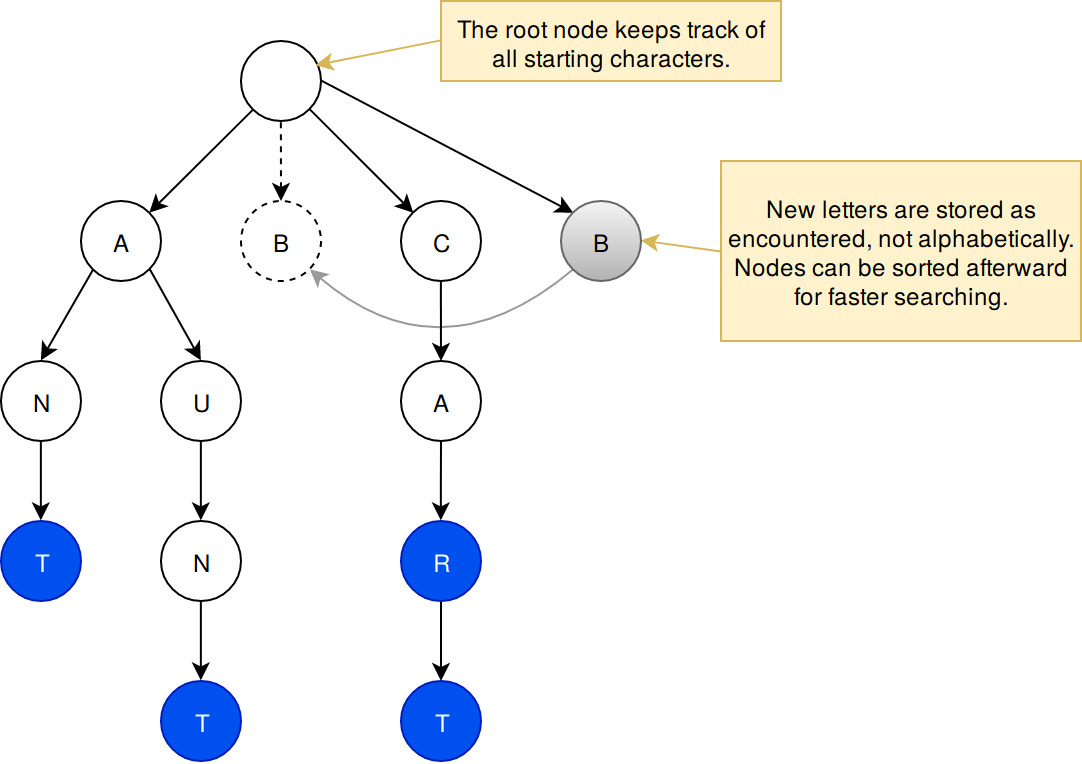
Ordering is not automatic in the data structure. When new paths are encountered, they are stored at the end of the data structure. For small prefix trees, it is not necessary to sort the structure. However, implementations that are built for high capacity and high speed searches on a slow medium such as a hard drive or SSD must sort nodes. This means sacrificing some adding speed, when searches are concurrently being done.
Leave a Reply
You must be logged in to post a comment.